Python sorted()와 key 정렬기준 최적화 과정
1. 들어가기에 앞서
들어가기에 앞서 말하자면 이 글은 가설을 세우고 다시 정정하는 과정을 담고 있다. 따라서 가설이 맞다고 생각하면서 읽기보다는, 그 과정에서 어떤 오류가 있었는지를 살펴보면 더 유용할 것이다.
2. sorted()에서 같은 정렬 기준을 사용했는데, 실행 속도가 다르다
코딩 테스트 문제 리트코드937 - 로그 파일 재정렬을 풀다가 예상보다 정렬 속도가 느리게 나오는 경우를 발견했다. 교재에 있는 답안을 그대로 제출했더니 전체 제출된 답안의 런타임 중에 좌측과 같은 분포가 나타났고, 그 후 다른 답안을 참고하여 sorted()의 key 파라미터를 수정하여 제출했더니 우측의 분포가 나타났다.
내가 참고한 교재에서는 정렬 시 아래와 같은 방법(A)을 사용한다.
sorted(logs, key=lambda x: (x.split[1], x.split[0]))
런타임이 짧은 답안(B)은 아래와 같다.
def get_key(log):
_id, rest = log.split(" ", maxsplit=1)
return (0, rest, _id) if rest[0].isalpha() else (1, )
return sorted(logs, key=get_key)
| 교재 답안 | 리트코드 참고 답안 |
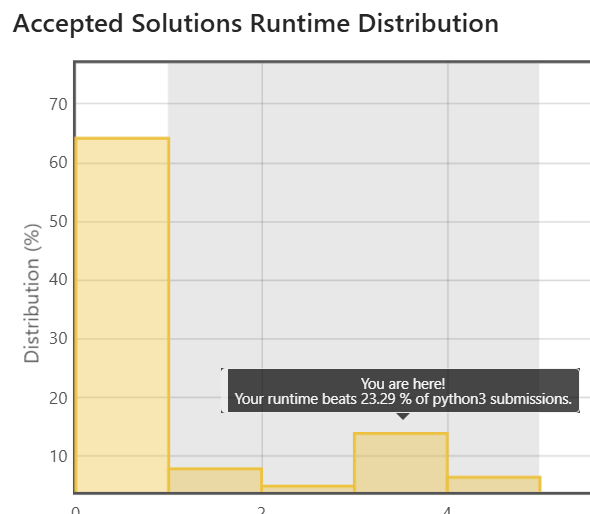 |
 |
런타임에 유의한 차이가 있어보여 어떻게 이런 차이가 발생하였는지 알아보기로 했다.
3. 가설: lambda와 사용자 정의 함수의 차이
처음에는 A는 사용자 정의 함수를 따로 선언했기 때문에 stack에 저장되는 지역함수이고, 람다는 익명함수이기 때문에 이런 차이가 발생한다고 생각했다.
- lambda는 Python에서 실행될 때마다 새로운 함수 객체를 생성할 수 있다.
- 정렬할 때마다 새로운 lambda 객체가 생성되는 게 아닐까?
- 반면, def 함수는 heap에 저장되므로 한 번 정의된 후 재사용될 것이다.
→ 이 가설이 맞다면, lambda가 느려지는 원인은 메모리 구조(stack vs heap) 때문일 것이다.
4. 실험: lambda가 문제라면, 단순한 lambda도 느려야 한다
letters.sort(key=lambda x:(x[1], x[0]))
letters = [idf + " " + cont for idf, cont in letters]key의 lambda에서는 이미 계산된 값으로 비교하여 간단한 연산만 하도록 코드를 수정하였다. lambda를 사용하면 언제나 속도가 느려야 한다. 하지만 실험 결과, 단순한 lambda를 사용할 때는 속도 차이가 거의 없었다.

lambda를 사용했다고 해서 항상 느려지는 것은 아니다. 단순한 lambda는 속도 차이가 거의 없었다. 문제는 lambda 자체가 아니라 key 정렬 기준 내부의 연산량이었다.
5. 새로운 가설: split()이 반복 실행되는 것이 문제다
Python의 공식 문서인 "Sorting HOW TO"에서는 sorted() 함수의 key 매개변수에 대해 이렇게 설명한다.
The value of the key parameter should be a function (or other callable) that takes a single argument and returns a key to use for sorting purposes. This technique is fast because the key function is called exactly once for each input record.
파이썬은 sorted()로 정렬시 각 입력값마다 정확히 key가 한 번씩 호출되며, 이는 성능을 높이기 위해 설계된 작동이다. 즉, key 함수는 정렬 과정에서 각 요소마다 한 번만 실행된다.
런타임이 오래 소요되는 코드를 다시 보면 불필요한 반복이 있다.
sorted(logs, key=lambda x: (x.split[1], x.split[0]))sorted()는 각 요소에 대해 key 함수를 한 번만 호출하지만, lambda 내부에서 split()을 불필요하게 두 번 실행했기 때문에 정렬 속도가 저하되었다.
속도가 빠른 두 코드 모두 split을 한번만 실행한다. 한 번 실행해서 될 것을 두 번씩 반복했으므로 속도가 늦어지는 것은 당연하지만 당시에는 이게 잘 보이지 않았다는 게 신기하다.
letters.sort(key=lambda x:(x[1], x[0]))
letters = [idf + " " + cont for idf, cont in letters]def get_key(log):
_id, rest = log.split(" ", maxsplit=1)
return (0, rest, _id) if rest[0].isalpha() else (1, )
return sorted(logs, key=get_key)- split()이 요소마다 한 번만 실행
- 정렬 과정에서는 이미 저장된 key 값만 사용되므로 추가 연산이 발생하지 않음
- key 함수 내부의 중복 연산을 제거하여 성능을 최적화.
6. 추가적인 발견: lambda와 def 함수의 실행 방식 차이도 속도에 영향을 줄 수 있다
이제 split()이 불필요하게 실행된 것이 성능 저하의 핵심 원인이라는 것을 알았다. 하지만 또 하나 발견한 것이 있다.
- lambda는 실행될 때마다 새로운 함수 객체를 생성할 가능성이 있다.
- def 함수는 한 번 정의되면 메모리에 저장되고 재사용된다.
→ 연산량 자체도 성능에 가장 큰 영향을 미치지만, 함수가 어떻게 정의되었는지도 성능 차이를 만들 수 있다. 특히, 호출 횟수가 많아질 경우 lambda는 매번 새로운 함수 객체를 생성할 가능성이 있어, def 함수보다 약간 더 느려질 수 있다.
하지만 현재 이 케이스에서는 차이가 미미하며, 핵심 원인은 split()의 중복 실행이다.
즉, lambda가 느린 것이 아니라, lambda 내부의 비효율적인 연산이 문제였다.
7. 최종 결론: 문제는 lambda가 아니라, 불필요한 연산이다
정렬 속도 차이의 핵심 원인은 lambda 자체가 아니라, split()이 반복 실행되면서 불필요한 연산이 발생한 것이었다.
하지만 같은 연산량이라도 함수가 어떻게 정의되었는지가 성능에 영향을 줄 수 있다.
특히, 호출 횟수가 많아질 경우 lambda는 매번 새로운 함수 객체를 생성할 가능성이 있어, def 함수보다 약간 더 느려질 수 있다.
sorted 연산을 정렬 속도를 최적화하기 위해:
- key 정렬 기준에서 불필요한 연산을 줄인다.
- 한 번 계산할 수 있는 값은 한 번만 계산한다.
결론: sorted()를 사용할 때 key 정렬 기준을 신중하게 설계해야 한다. 작은 차이 하나가 예상보다 큰 성능 차이를 만들 수 있다
https://docs.python.org/3/howto/sorting.html
https://docs.python.org/ko/3.13/howto/sorting.html
https://leetcode.com/problems/reorder-data-in-log-files/description/
'Python' 카테고리의 다른 글
| [Python] raw string 사용법 / 코드업 6008번 문제 (0) | 2022.02.18 |
|---|

댓글